
INTRODUCTION *
1 Analyse et conception objets *
1.1 Rappels sur les concepts objets *
1.1.1 Définitions *
1.1.2 Propriétés *
1.2 Analyse et conception objet *
1.2.1 Les concepts *
1.2.2 Les dimensions statiques, dynamiques et fonctionnelles *
1.2.3 Les cartes CRC (Classes, Responsabilités, Collaborateurs) *
1.2.4 Le prototypage *
1.3 Panorama des méthodes d’analyse et de conception objet *
1.3.1 OOADa (Object Oriented Analysis and Design with applications) *
1.3.2 OOSE (Object Oriented Software Engineering) *
1.3.3 HOOD (Hierarchical Object Oriented Design) *
1.3.4 OOA/OOD (Object Oriented Analysis / Object Oriented Design) *
1.3.5 OMT (Object Modeling Interface) *
1.3.6 Merise orienté objet *
2 Implantation, métriques et tests *
2.1 Les langages objets *
2.1.1 Implantation d’application dans les méthodes objets *
2.1.2 Simula *
2.1.3 Smalltalk *
2.1.4 ADA *
2.1.5 C++ *
2.1.6 Eiffel *
2.1.7 Java *
2.1.8 Object Pascal *
2.2 La métrologie objet *
2.2.1 Introduction sur les métriques objets. *
2.2.2 Métriques de contexte classe *
2.2.3 Métriques de contexte application *
2.2.4 Métrique de couplage : CBO *
2.2.5 Métriques d’héritage *
2.2.6 Les métriques de visibilité et de masquage de l’information *
2.3 Les tests *
2.3.1 Introduction aux tests objets *
2.3.2 Les tests unitaires *
2.3.3 Test en boîte blanche, test en boîte noire *
3 Les avantages et les inconvénients *
3.1 L’augmentation de la qualité *
3.1.1 Définition rapide de la qualité *
3.1.2 L’apport des méthodes objets *
3.1.3 La modularité *
3.2 La réutilisation *
3.2.1 Ses apports *
3.2.2 Ses contraintes *
3.3 Les inconvénients *
3.3.1 Les coûts et les surcoûts *
3.3.2 Les problèmes d’adoption *
4 Utilisation et évolution des méthodes de développement objets *
4.1 Utilisation *
4.1.1 Les interfaces graphiques utilisateur (IGU) *
4.1.2 L’objet et les bases de données *
4.1.3 La gestion de projet *
4.2 Evolution *
4.2.1 UML (Unified Modeling Language) *
4.2.2 COBOL orienté-objet *
4.2.3 Les outils de développement *
4.3 Le middleware objet *
4.3.1 L’OMG *
4.3.2 CORBA (Common Object Request Broker Architecture) *
4.3.3 OLE/COM (Object Linking and Embedding/Common Object Model) *
CONCLUSION *
BIBLIOGRAPHIE *
Une méthode est un processus en cascade visant à rétrécir le champs des solutions. Une méthode de développement objet est donc un ensemble de processus, de techniques de modélisation objet et de biens livrables. Les processus guident les développeurs à produire un système informatique. Les techniques de modélisation permettent d’exprimer formellement un système ou un composant, à différents niveaux de détails. Le concept objet est utilisé dans chaque étape de représentation, de l’expression des besoins aux tests. Un bien livrable est le produit d’un processus accompli avec une ou des techniques de modélisation.
Le modèle objet est apparu en 1965. Ole Dahl et Kristen Nygaard, deux chercheurs norvégiens, ont mis en œuvre durant cette année un mécanisme d’abstraction couplé à un mécanisme de raffinement de classe (héritage). Le premier langage à regrouper données et procédures fut Simula I, en 1966. Simula, son successeur a ensuite formalisé le concept d’objet (ou instance de classes). Simula a servi de modèle à toute une lignée de langages caractérisés par un typage statique (C++, Eiffel, …).
L’abstraction a été formalisée dans les années 70 avec la théorie des types abstraits. L’idée fondamentale était tout d’abord de définir un ensemble de fonctions (empiler, dépiler) manipulant un ensemble de sortes (entiers, réels). Ensuite, ces fonctions et ces axiomes étaient spécifiés formellement, sans se préoccuper de l’implémentation.
Parallèlement, le langage Smalltalk s’est développé. Il est la source d’inspiration essentielle de l’approche objet. Il a implémenté la notion de type abstrait sous forme de classe, l’envoi de messages et la structuration des classes en hiérarchie de généralisation avec héritage.
De nombreuses méthodes de conception objet ont été proposées depuis les années 70. Leur développement a été influencé par les technologies des langages objets. Elles ont contribué à mieux définir les étapes de conception et surtout à standardiser le vocabulaire et les représentations utilisés par les concepteurs et les développeurs. L’analyse objet est apparue plus tard (dans les années 80), afin de combler le manque qui existait dans le cycle de développement du logiciel.
L’approche objet a dépassé depuis quelques années le cercle restreint des chercheurs et autres spécialistes. Cet attrait est la conséquence de la crise du logiciel. La complexité, la taille grandissante des applications, les nouvelles exigences des utilisateurs et les problèmes de maintenance ont mis en évidence la nécessité de trouver un solution. En effet, des estimations montrent que pas plus de 15% de code écrit chaque année dans le monde est original. Ce constat a amené à mieux réorganiser les programmes et les pensées afin de réutiliser les 85% du code au lieu de les réécrire.
La technologie objet fournit une opportunité d’augmentation de productivité et une meilleure réponse à la complexité grâce entre autres, à ses possibilités de réutilisation et son approche modulaire. Mais, l’utilisation d’une technologie nouvelle et encore jeune comporte des risques et il certains projets se sont révélés être désastreux. Du recul est donc nécessaire afin d’appréhender le mieux possible le monde et la philosophie objets.
Le premier chapitre introduit les notions d’objets, de classes ainsi que leurs propriétés. Ensuite, nous étudions les méthodes d’analyse et de conception objets. Celles-ci doivent prendre en compte les propriétés des classes et des objets présentées auparavant. Les méthodes OOADa, OOSE, HOOD, OOA/OOD, OMT et OOM sont présentées et illustrées.
Le deuxième chapitre présente l’implantation d’applications et les langages objets comme Simula, Smalltalk, Java, etc. Puis, nous définissons le rôle des métriques objets et nous décrivons différents métriques ainsi que leur utilisation. Nous nous intéressons ensuite aux tests et à leur mise en application. Les objets nécessitent des métriques et des tests supportant leurs différences par rapport aux méthodes traditionnelles.
Le troisième chapitre fait le point sur les avantages et les inconvénients des méthodes de développement objets. Nous commençons par étudier l’augmentation de la qualité, en montrant quelles propriétés sont responsables de cet accroissement. Ensuite, nous nous intéressons plus particulièrement à la notion de réutilisation, avec ses atouts mais aussi ses contraintes. Nous finissons par les inconvénients dus aux coûts et aux problèmes d’adoption des méthodes objets.
Le dernier chapitre développe les utilisations et les évolutions de la technologie objet. Nous étudions d’abord les interfaces graphiques utilisateur. Puis, nous présentons les deux solutions pour gérer des bases de données objets : les SGBDRO et les SGBDO. Le chapitre développe ensuite une approche de gestion de projet tenant compte des méthodes objets. La méthode UML, Cobol orienté objet et une étude sur les outils objets suivent cette approche. Nous finissons en nous intéressant au middleware objet avec CORBA et OLE/COM.
Ce premier chapitre introduit la terminologie des concepts objets. Celle-ci sera utile pour comprendre l’analyse et la conception objets étudiées ensuite. Ces deux étapes sont essentielles puisqu’elles apportent une démarche afin de produire un modèle de données et une analyse des comportements des objets. La conception enrichit le modèle d’analyse par l’ajout de nouvelles classes, méthodes, etc.
Un objet est un élément du monde réel. Il est caractérisé en informatique par (cf. figure 1) :
L’interface est la partie visible de l’objet. L’implémentation est la partie cachée.
Une classe regroupe les caractéristiques communes des objets de même nature et les classifie. Elle est définie par :
Au moins deux niveaux de visibilité externe des opérations sont souhaitables : public et privée. Les opérations publiques constituent l’interface de la classe, et sont accessibles à tout utilisateur de la classe. Les opérations privées servent à supporter les opérations publiques et ne sont accessibles qu’à l’implémentation de la classe.
La spécification d’une opération est fournie par sa signature qui définit le type des arguments d’entrée et de sortie.
Les objets et les classes communiquent entre eux en s’échangeant des messages. C’est aussi le seul moyen d’activer un objet et de déclencher une opération. L’ensemble des messages auxquels peut répondre un objet (son comportement) est présenté à ses utilisateurs dans un protocole de communication.
Les opérations offertes par un objet sont classées en trois catégories. Les constructeurs altèrent l’état de l’objet, les sélecteurs retournent l’état de l’objet et les itérateurs permettent d’accéder à toutes les composantes de l’objet.
Un objet appartient, selon les opérations qu’il offre à une des trois catégories suivantes. Les acteurs requièrent des opérations mais n’en offrent pas. Les serveurs offrent des opérations mais n’en requièrent pas. Les agents offrent et requièrent des opérations.
L’encapsulation a pour but de séparer l’aspect externe d’un objet des détails d’implantation. Elle permet d’atteindre deux objectifs. Le premier est d’offrir au niveau de la modélisation un concept d’objet sans avoir à se soucier des problèmes d’implantation. Le second donne le choix au niveau de l’implantation, d’un langage de programmation afin de coder les méthodes et associer à une opération la ou les méthodes appropriées.
L’héritage simple est un mécanisme de transmission des propriétés d’une classe vers une sous-classe. L’héritage multiple est un mécanisme par lequel une sous-classe hérite des propriétés de plus d’une super-classe (cf. figure 2).

Le mécanisme d’héritage permet à un objet d’hériter d’attributs et d’opérations comme vu précédemment. Or, il s’avère intéressant de les redéfinir dans certains cas. Le mécanisme de surchargement autorise que les noms des attributs et opérations hérités soient conservés et que leur définition puisse être changée. L’extension ajoute certaines fonctions au comportement prévu tandis que la restriction limite l’action des opérations.
La généralisation est une fonction qui, à une classe d’origine, dite sous-classe, fait correspondre une classe plus générale, dite super-classe. L’action inverse, d’une super-classe vers une sous-classe est appelée spécialisation.
Le polymorphisme est la faculté d’une opération à pouvoir s’appliquer à des objets de classes différentes. C’est donc la capacité donnée à différents types de réagir à la même opération, chacun à sa façon. L’objet type qui émet une requête n’a pas à connaître le type du receveur. De ce fait, le type receveur importe peu pourvu qu’il offre l’opération considérée. Dans cet échange, l’interprétation de l’opération à réaliser est déterminée par le type receveur.
L’association est une relation entre plusieurs classes, caractérisée par un verbe, décrivant conceptuellement les liens entre les objets et la classe. L’association possède une cardinalité qui contraint le nombre d’objets maximum connectés à chaque objet. Un cas particulier d’association est l’agrégation (cf. figure 3). Elle représente la relation partie de. Elle est utile pour modéliser les objets complexes.

L’analyse objet (ou modélisation objet) est une analyse du monde réel. Elle décrit un problème à résoudre et répond à la question " Quoi ? ". Son résultat est un modèle qui comprend un certain nombre d’objets. Chacun des objets modélisés correspond à un objet du monde réel. Ils sont alors appelés des objets sémantiques.
Le modèle objet est une abstraction concise et précise de ce que le système désiré doit faire. Un bon modèle doit être compris et critiqué aussi bien par des programmeurs que des experts de l’application.
La conception objet est la conception d’un système basé sur les objets. Elle décrit la solution du problème et répond à la question " Comment ? ". Cela implique la traduction en un système logiciel de son architecture globale, des structures de données et des algorithmes des principaux objets. Lors de la conception, de nouveaux objets peuvent être définis pour des raisons d’implantation.
Les méthodes d’analyse et de conception sont caractérisées par :
La plupart des méthodes objets ont une approche commune basée sur une triple perception du système d’information (cf. figure 4).

La dimension statique définit les objets en se concentrant sur les structures de données que l’objet représente, ainsi que sur les opérations qui peuvent être faites sur ces objets.
La dimension dynamique définit un objet parce qu’il représente une entité qui possède un comportement intéressant :
Les objets sont vus ici comme des agents coopérants et collaborants.
La dimension fonctionnelle n’est pas comprise de la même façon dans toutes les méthodes. Certaines l’assimilent à la description des fonctionnalités du système d’information. D’autres l’associent à la spécification détaillée des opérations définies sur les objets.
Ces trois dimensions sont complémentaires. Elles concourent toutes à décrire de façon la plus complète possible le système d’information.
Les cartes CRC sont une technique pour la conception de classes développée par Beck et Cunningham. Chaque classe (sans distinction entre les classes et les objets) est inscrite sur une carte CRC avec son nom, ses responsabilités et ses collaborateurs.
La responsabilité correspond aux problèmes résolus par la classe. L’ensemble des problèmes est appelé contrat. Les collaborateurs sont les classes liées à la classe définie. Les classes liées fournissent les services qui permettent à une classe de satisfaire des responsabilités contractuelles.
Les cartes CRC sont utilisées comme un instrument de départ pour la modélisation de classes. C’est aussi un outil de conception très efficace lorsqu’il est utilisé après la modélisation.
Le prototypage objet confirme que le modèle informatique provenant des phases d’analyse et de conception correspond bien au modèle du monde de l’entreprise. Les données ne sont pas exposées directement aux manipulations de l’utilisateur. Le prototypage est seulement représenté en terme d’objets et on n’accède à ceux-ci qu’à travers leurs méthodes.
Il existe deux types de prototypes : le prototype d’analyse et le prototype de domaine. Le premier sert uniquement à informer l’utilisateur et à prouver le concept. Il ne sert pas de base pour le développement. Le deuxième est une aide pour l’implantation incrémentale d’une solution. Il montre la faisabilité de l’implantation et pourra évoluer vers un produit livrable.
L’OOADa (proposée par Booch) se concentre plus sur des questions de conception que sur le processus d’analyse. Cette méthode produit différentes vues (ou modèles) afin de faire ressortir toutes les décisions relatives à la conception.
L’OOADa se déroule selon quatre étapes majeures :
Cette méthode crée une vue logique du modèle objet. Cette vue dépeint les structures des classes et des objets ainsi que les relations (analyse), sans contraintes d’implantation.
Dans la phase de conception, le modèle prend en compte les considérations d’implantation. On obtient alors une vue physique.
La méthode OOSE est une méthode suédoise qui a intégré l’approche objet d’une façon originale en 1992. En effet, elle définit un système d’information avec les objets et leur comportement, une description des interfaces utilisateurs et les objets de contrôle. Ces derniers vérifient le comportement de plusieurs objets simultanés. Leur but est de modulariser le système, de limiter l’impact des modifications par le masquage des objets et d’atténuer leur dynamique grâce aux interfaces.
La méthode est préconisée pour les applications de gestion et les applications temps réel. Elle se décompose en cinq modèles de description (cf. figure 5) :

le modèle de test vérifie la cohérence interne du système constitué.
Le modèle des besoins
OOSE introduit la notion des cas d’utilisation d’Ivar Jacobson. Ils décrivent le comportement du système du point de vue de l’utilisateur. Ils définissent les limites du système et ses relations avec l’environnement.
Un cas d’utilisation est un schéma qui comprend un ensemble d’événements provoqué par un acteur. Les interactions entre l’acteur et le reste du système sont ensuite spécifiées. Tous les cas d’utilisation spécifient les moyens existants pour utiliser le système dans sa globalité.
Quatre grandes catégories d’acteurs existent. Après les avoir identifiés, ils sont décrits plus précisément. Les acteurs principaux sont les personnes qui utilisent les fonction principales du système. Les acteurs secondaires sont les personnes qui effectuent des tâches administratives et de maintenance. Le matériel externe englobe les dispositifs matériels périphériques (imprimantes, lecteurs optiques, ...). Les autres systèmes sont les systèmes avec lesquels le système interagit.
Les cas d’utilisation représentent des scénarios. Ils décrivent ce que chaque objet peut attendre des autres objets. Ils définissent l’interface de l’objet.
Cette étape produit un modèle informel d’analyse qui correspond à une expression des besoins.
Le modèle d’analyse
Le modèle est une description cohérente de l’ensemble des vues qui le compose. Le système est décrit vue par vue avec un ensemble de liens entre ces vues.
Les objets correspondent ici aux noms du domaine du problème à résoudre. Leur classification est ensuite nécessaire pour obtenir une hiérarchie de classes. Il est donc nécessaire de trouver les similitudes entre les objets afin de les regrouper.
Les modèles de conception et d’implantation
Le passage du niveau conceptuel au niveau logique, puis du niveau logique au niveau physique doit respecter le principe de traçabilité. La traçabilité conserve l’identité des objets tout au long du cycle de développement. Cela permet de les identifier plus facilement et de décrire les impacts éventuels d’une modification.
Le niveau conceptuel ne prend en compte que les caractéristiques générales de l’environnement choisi. Les différentes catégories d’objets sont alors représentée par des blocs. Un diagramme d’états et un diagramme d’interactions sont associés à chaque bloc.
Le niveau d’implantation correspond à la phase de codage des blocs. Ce codage peut se faire soit dans un langage traditionnel, soit dans un langage objet. Il doit tenir compte de la nature des traitements de l’application (par lots, transactionnelle, temps réel).
Le modèle de test
Il se décompose en trois étapes : le test unitaire, le test d’intégration et le test du système. Ces étapes produisent des rapports d’évaluation sur la qualité du système construit.
La démarche de conception utilisant les cas d’utilisation intègre mieux l’aspect modulaire et incrémental du système d’information. Son cycle de développement est assez complet par rapport à d’autres méthodes. Mais, sa double approche systémique et structurée est utilisée sans préciser le passage de l’une à l’autre. De plus, son modèle conceptuel n’apporte pas une sémantique claire des
associations entre les différents objets (entités, interfaces et contrôles).
HOOD a été développée par un consortium de société suite à un appel d’offre lancé en 1986 par l’ESA (Agence Spatiale Européenne). Cette méthode répond à un besoin de conception en temps réel. Elle couvre toute l’étape de conception architecturale. Elle se compose d’un modèle objet qui est globalement celui proposé par Booch. Les objets sont vus comme des machines abstraites qui sont perfectionnées progressivement.
Le processus de conception est globalement descendant. La première étape consiste à trouver l’objet parent de haut niveau, c’est à dire le système à concevoir.
Ensuite, vient la formalisation de la stratégie. Elle identifie dans un premier temps les objets et les opérations. Puis, elle regroupe les objets et les opérations. Enfin, elle établit la visibilité entre les objets par l’utilisation de diagrammes HOOD montrant les relations parent/enfant, les opérations, les hiérarchies d’utilisation, les liens, le flot des données et les exceptions.
La dernière étape consiste à :
HOOD définit deux types d’objets. Les objets passifs ont un comportement séquentiel, comme dans les autres méthodes. Par contre, les objets actifs se comportent de manière parallèle afin de répondre aux besoins du temps réel.
La méthode introduit une relation d’inclusion entre objets. Cela signifie qu’un objet inclut un autre objet (ou est composé d’objets fils). En effet, les hiérarchies de classes et l’héritage ne sont pas pris en compte par HOOD.
Un objet nœud virtuel est défini dans HOOD pour la conception de systèmes distribués. Un objet nœud virtuel est vu comme l’abstraction d’un logiciel qui s’exécute sur un nœud physique particulier. Les activités d’un tel objet se composent d’opérations locales, de communications ou de coordination avec d’autres nœuds virtuels.
La méthode HOOD a la capacité de représenter des objets complexes et de définir le contrôle des interactions entre objets. Mais, elle ne s’attache qu’à la dimension statique des applications. De plus, elle ne couvre que le niveau logique de la conception.
La méthode OOA/OOD de Coad et Yourdon (1991) se focalise sur le niveau statique du modèle objet. Elle propose un seul modèle qui est une extension du modèle Entités-Attributs d’OOA. La généralisation, la spécialisation et l’agrégation y sont ajoutées.
La démarche se base sur cinq niveaux de spécification (cf. figure 6) :

Après avoir défini les sujets, il faut déterminer pour chacun d’eux les objets qui les composent. Ensuite, il faut trouver les relations et les associations des objets. Pour finir, il faut décrire le détail des objets en termes d’attributs, d’opérations et de messages.
Cette démarche peut être utilisée au niveau conceptuel et logique. Il n’y a pas de représentations ou de notations différentes pour ces deux niveaux. Des objets techniques supplémentaires peuvent être ajoutés au niveau logique pour des besoins d’implantation.
En plus des niveaux de spécification vus plus haut, le niveau logique étudie trois autres domaines. Le premier se nomme le domaine des interactions homme-machine. Il décrit les interfaces et les protocoles de communication entre l’application et les utilisateurs.
Le deuxième correspond au domaine de la gestion des tâches. Il définit et coordonne les différentes tâches du système (les transactions). Et enfin, le domaine de gestion des données décrit les différents moyens de stockage, d’accès et de gestion des données.

OMT est une méthode complète d’analyse et de conception. Elle a été inventée dans le Centre de Recherche et Développement de General Electric à la fin des années 80. Le cycle de développement d’OMT est un cycle en cascade où seules les itérations vers l’étape précédante sont permises (cf. figure 7).
La partie analyse est décomposée en une entrée initiale, une sortie et à une construction d’un dictionnaire des données.
L’entrée initiale est un état du problème. Il décrit le problème à résoudre et fournit un survol conceptuel du système. La sortie est un modèle formel. Il comprend :
Le dictionnaire des données décrit :
OMT subdivise un système en trois modèles distincts. Le modèle objet décrit la partie statique du système. Elle utilise pour ce faire une extension du modèle Entité-Association. Le modèle dynamique définit les divers états des objets et leur évolution en réaction à divers événements (diagrammes d’états/transitions, diagrammes d’événements). Son objectif est la description du cycle de vie des objets. Le modèle fonctionnel décrit la structure opérationnelle en termes de valeurs et de fonctions par des flux de données (diagrammes de flux de données).
La conception se décompose en deux phases : la conception du système et la conception des objets. La première détermine l’architecture globale. Ensuite, le système est organisé en sous-systèmes grâce à l’utilisation du modèle objet. La deuxième phase met en jeu le concepteur. Il choisit les algorithmes basiques pour implanter chaque fonction majeure du système. Puis, il détermine l’implantation des relations entre les objets et des attributs des objets.
Cette méthode favorise une concentration de l’effort de développement sur la phase d’analyse du cycle de vie (de la spécification formelle à l’implémentation). Elle offre un modèle objet riche et une représentation graphique très conviviale. Cependant, l’identification des opérations se fait de manière trop tardive.
Merise est utilisée par environ 70% des entreprises en France depuis la fin des années 70. Elle a joué un rôle important dans l’acquisition d’un cadre et d’un langage communs pour les concepteurs et les développeurs. Elle doit aujourd’hui faire face aux méthodes objets et propose sa méthode incluant les concepts objets.
Les orientations objets dans Merise (OOM) ont pour but de réunir, en une même formalisation, la modélisation des données (Modèle Conceptuel de Données) et celle des traitements (Modèle Conceptuel de Traitements). Elles sont une variante de la méthode de base complétée par de nouveaux mécanismes de modélisation. Les acquis précédents ne sont donc pas remis en cause.
Le modèle entité-association retenu permet la représentation des propriétés multi-valuées (comme PRENOMS) ou encore la représentation des agrégats (comme ADRESSE). Le modèle structuré de traitements découpe chaque opération conceptuelle en un certain nombre d’occurrences de phases-types (création d’une occurrence, mise à jour d’une propriété, …). Ce sont ces phases qui sont associées à la modélisation des données et qui indiquent l’action à effectuer sur les occurrences d’une entité, d’une association, d’une propriété.
Dans OOM, la structure des objets est pilotée par les données. La sémantique qui leur est rattachée provient donc des données qui donnent à l’objet sa signification et son identité. Par contre, les associations donnent lieu à l’apparition d’objets partagés. Ils sont identifiés par la concaténation des identifiants des objets qui les partagent.
La modélisation OOM passe par l’élaboration d’une modélisation de données Entité-Relation (Modèle Externe de Données). Celle-ci est ensuite transformée en une structure objet encapsulant les traitements (Modèle Externe Objet). Le MEO est centré sur un objet unique appelé " client ". Cet objet inclut les échanges qu’il entretient avec son environnement.
Par rapport aux autres méthodes, OOM se situe comme OMT et OOSE avec son style de conception-développement recouvrant le plus d’étapes. Cependant, OOM est plus riche dans la spécification des contraintes et des règles. Mais, elle n’intègre pas les interfaces homme-machine. C’est une méthode jeune et donc en pleine évolution.
Un grand nombre de méthodes d’analyse et de conception existent. Leurs terminologies sont suffisamment différentes pour induire des erreurs de compréhension et d’ambiguïté chez les utilisateurs. De plus, ces méthodes ne couvrent pas toujours tout le cycle de développement et il est parfois impossible d’utiliser telle méthode pour l’analyse, puis telle autre pour la conception.
Les langages objets existent depuis la fin des années 60. Aujourd’hui, le choix d’un langage est difficile puisqu’il faut considérer les caractéristiques et les exigences de chaque application et tenter d’y appliquer l’outil le mieux adapté. Il est donc nécessaire d’identifier les capacités propres de chaque langage.
Dans tous les domaines industriels, des instruments de mesure existent afin de juger de la qualité de la fabrication d’un produit. Ce sont ces instruments de mesure que nous étudions dans la deuxième partie de chapitre.
L’utilisation des tests est primordiale puisque le but des méthodes objets est la réutilisation des composants. Une phase de tests hâtive peut entraîner une cascade d’erreurs dans la réutilisation de ces objets.
La programmation objet convertit les classes de conception en des programmes. Ils sont organisés en ensemble coopérant de classes. La plupart sont les membres d’une hiérarchie de classes liées par un héritage.
Toute activité de développement peut tirer un avantage de l’utilisation d’un catalogue qui emmagasine les résultats d’une phase de développement pour les utiliser dans la suivante. Les outils CASE sont utilisés dans le processus de développement à la fois pour la modélisation et pour l’accès à ce catalogue. Ils ne servent que pour les projets de grande et moyenne taille (cf. chapitre 4.2.3).
Les outils de documentation servent pour les petits projets. Ils ne couvrent qu’une partie du processus. Un travail manuel est nécessaire afin de transformer la sortie d’une phase de développement en entrée dans la suivante. Ils doivent aider l’utilisateur à organiser l’information et à reconnaître :
Simula est le premier langage à objets. Crée en 1967, il se fonde sur des travaux antérieurs reposant sur un langage spécialisé dans la simulation par événements discrets (Simula 1).
Simula définit des classes avec des attributs et des procédures privées ou publiques. Il ne reconnaît que l’héritage simple et les classes. Il supporte le mécanisme de fonctions virtuelles et la récupération automatique de la mémoire (appelée ramasse-miettes dans le jargon informatique). Les objets ont une existence propre. Ils correspondent à des programmes qui sont activés dès qu’ils sont crées.
L’encapsulation est réalisée par la " protection d’un trait " qui évite à l’information de se transmettre aux descendants. De plus, il gère les processus simultanés déclenchables à des instants précis.
C’est un langage compilé, fourni avec une bibliothèque de classes spécialisée dans la simulation par événements discrets.
Smalltalk est disponible sur la plupart des systèmes existants. Son code source est portable d’une plate-forme à l’autre. Sa première version date du début des années 70. Elle est le fruit du travail d’une équipe de recherche de Xerox Corporation. Le travail sur Smalltalk a fait passer le terme " orienté objet " dans le langage et a été une source d’inspiration des interfaces graphiques pour les systèmes actuels.
Dans Smalltalk, tout est objet (la notion d’entier n’existe pas). Il gère les objets, les classes, l’héritage simple, l’envoi de messages et le polymorphisme. La récupération de mémoire se fait automatiquement à l’aide d’un ramasse-miettes.
Smalltalk a introduit la notion de métaclasse qui n’existait pas dans les autres méthodes. Une métaclasse représente une classe de classes qui ne peut être instanciée. Elle représente un concept abstrait. Par contre, les classes héritées de la métaclasse représentent des concepts plus concrets. Chaque classe est instance exclusive de sa métaclasse et la métaclasse n’est créée que lorsque la classe l’est.
Son environnement est interactif et complet. Il comprend un interpréteur, une bibliothèque de classes, un debugger, un inspecteur de variables et un browser de classes. La compilation s’effectue de manière dynamique.
C’est un excellent langage pour des applications interactives et pour s’initier aux langages objets car il ne permet aucune dérive vers le non-objet. Mais, il ne supporte pas la notion d’objets persistants et ne détecte les erreurs d’envoi de messages qu’à l’exécution.
ADA a vu le jour à la fin des années 70. Ses fondateurs sont Jean Ichbiah et son équipe de la Société BULL. C’est un langage " temps réel " à base d’objets. Il gère l’héritage multiple, le polymorphisme et la surcharge des fonctions et opérateurs depuis sa mise à jour en 1995.
ADA fonctionne avec des " packages " et non des classes. Il n’existe donc pas de mécanisme d’instanciation. Les packages groupent des types abstraits et des fonctions logiquement reliées. Ils sont définis par leur spécification (nom, types, fonctions) et leur implémentation.
C’est un langage compilé qui génère, selon ses auteurs du code efficace, fiable et maintenable. Il supporte le multitâche et gère les accès concurrents grâce à des mécanismes de protection des objets partagés. Mais, ne permettant pas l’extension de types existants, il en découle une inévitable duplication de code. De plus, c’est un langage difficile à apprendre et à manipuler.
Il est fournit avec son compilateur, une librairie de développement, un éditeur, un debugger, un outil de test de performance et d’analyse du code et des outils de gestion du code source. Ada évolue vers un véritable langage à objets, avec des environnements de développement complets (ObjectAda de Thomson Software Product).
Le C++ est un langage hybride car il provient du C, auquel des constructions orientées objet ont été rajoutées. Il a été conçu par Bjarne Stroustrup au centre de recherche Bell Laboratories de ATT au début des années 80. Son objectif est de corriger les défauts du C en matière de typage et de structuration d’objets tout en maintenant la compatibilité et l’efficacité des programmes.
Le C++ supporte les classes, l’héritage multiple, le polymorphisme, la surcharge et les liaisons dynamiques. Une classe regroupe des variables et des fonctions membres. L’encapsulation est réalisée par la possibilité de rendre certains attributs privés. Mais dans ce langage, tout n’est pas objet : certaines données ont des types prédéfinis (entier, réel, ...).
En C++, chaque classe a deux méthodes implicites : le constructeur d’objet et le destructeur d’objet. Ces méthodes aident à la gestion de la mémoire. En effet, il n’existe pas de fonction ramasse-miettes automatique.
L’implémentation de l’héritage se fait par la définition de sous-classes (classes dérivées). Celles-ci héritent de toutes les propriétés des classes de base. Le C++ offre la possibilité de donner à une fonction des privilèges d’accès aux parties privées de plusieurs classes dont elle n’est pas membre. La fonction est alors déclarée amie (friend) des classes en question.
C’est un langage compilé, avec un typage statique ou dynamique.
Les avantages du C++ sont qu’il est attrayant pour les programmeurs connaissant le langage C et qu’il permet de manipuler des éléments du système au plus bas niveau. Son inconvénient majeur est que beaucoup de programmeurs l’utilisent de la même manière que s’ils développaient en C. L’approche objet est donc mise sur le banc de touche.
Eiffel a été conçu par Bertrand Meyer pour les applications scientifiques et la gestion. Il tente de répondre aux questions de validité, de robustesse, de portabilité et d’efficacité. Il gère les objets, les classes, les attributs simples ou complexes, les méthodes, l’héritage multiple, la surcharge et la récupération de la mémoire.
Le langage à objets Eiffel ne considère pas les classes comme des objets (typage statique). Une classe décrit l’implémentation d’un type de données abstraites. Elle encapsule les procédures (méthodes) et les attributs, qui sont regroupés sous le terme de primitives. Les primitives sont soit privées, soit publiques.
Eiffel apporte la notion d’assertion. Une assertion est un ensemble de propriétés formelles auxquelles les opérations d’un objet doivent obéir. Elle exprime soit des pré-conditions, soit des post-conditions, soit des conditions d’invariance. Les assertions, vérifiées à l’entrée et à la sortie des fonctions, facilitent la documentation, la mise au point et la fiabilité des programmes.
Eiffel supporte les collections, les métaclasses et la gestion d’exceptions. C’est un langage compilé incrémental en C. Il est fourni avec un générateur de code, un mécanisme de documentation automatique, une bibliothèque de composants réutilisables et un outil graphique pour la conception.
Le langage Java est un langage pur objet conçu et réalisé par Bill Joy et son équipe de chercheurs (Sun Microsystem). Il a pour but de créer des applications intégrées en réseau, notamment dans des pages Web. Il est devenu très populaire grâce à son succès pour développer de petites applications appelées " applets " intégrables dans les pages Web. Java 1.2 vise également le développement de logiciels complets et indépendants.
Java respecte les principes de base de l’objet, c’est à dire l’encapsulation, l’héritage simple , le polymorphisme et les liaisons dynamiques. Le langage intègre le multithread, c’est à dire la possibilité d’exécuter et de synchroniser plusieurs tâches en parallèle dans une même application. Par contre, il ne gère pas les opérateurs de surcharge ni l’héritage multiple.
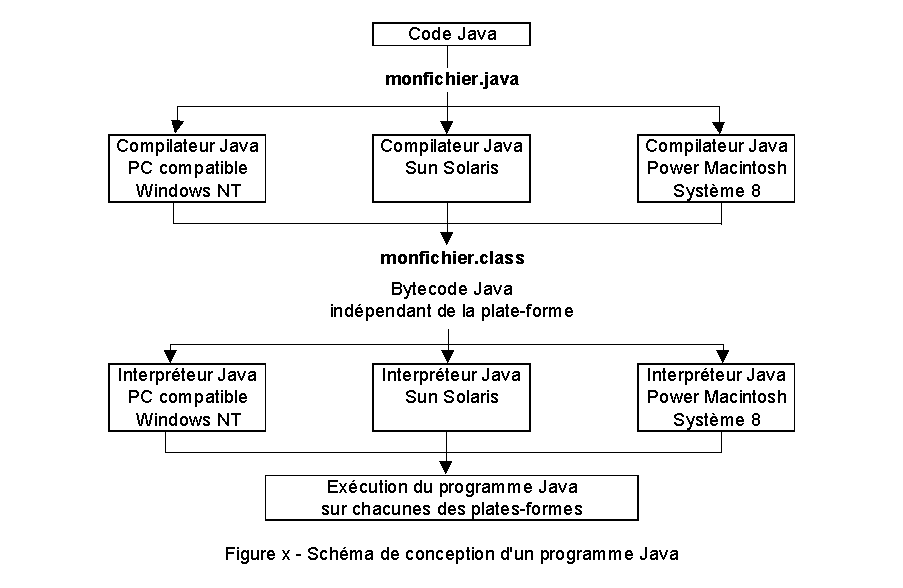
Il utilise un compilateur générant un code intermédiaire interprété (bytecode). Cela permet de compiler le code sans disposer des sources du composant et d’une manière dynamique (ce qui n’est pas le cas du C++). Un programme Java n’est donc pas exécuté mais est interprété par la machine virtuelle ou JVM (Java Virtuel Machine) qui est indépendante de toutes plates-formes (cf. figure 8).
Les protocoles d’accès au réseau tels que TCP/IP, HTTP, FTP sont fournis avec ce langage. Il est aussi possible d’implémenter le bus CORBA que nous verrons plus loin, dans le quatrième chapitre.
Java cache une partie de la complexité de C++. Il supprime les tâches fastidieuses que sont la gestion de mémoire et les pointeurs. Mais, ses performances seraient moins bonnes que du code C++ (à cause du code interprété) malgré un processus d’optimisation de l’interprétation du code appelé Just in Time.
Object Pascal est une extension du langage Pascal. Il a été développé au début des années 80 par Apple. Il supporte l’héritage simple, les liaisons dynamiques et la surcharge.
Avec Object Pascal, les types abstraits sont implémentés en type objet. Il est aussi possible de définir dans un type des propriétés privées qui ne sont pas héritées. L’objet est défini par une interface (attributs et signature des méthodes) et une implémentation donnant le corps des méthodes. Les types objets peuvent être regroupés en unités.
C’est un langage compilé à typage statique. L’environnement de développement Delphi est basé sur ce langage.
La métrologie est un instrument de mesure qui permet de juger de la qualité de la fabrication d’un produit. On définit alors des mesures minimales et maximales. Pour convenir, une réalisation doit se située dans les bornes fixées.
L’objet a amené à imaginer de nouvelles métriques pour prendre en compte ses concepts spécifiques : les classe, les attributs, les méthodes, l’héritage, l’utilisation. Les méthodes d’analyse et de conception objets peuvent bénéficier de ces mesures. Celles-ci permettent de découvrir des défauts dès la phase de conception.
Voici quelques outils de mesure :
Le nombre cyclomatique
Cette métrique donne le nombre de chemins linéaires indépendants dans un graphe fermé. C’est un indicateur de l’effort que doit faire un lecteur pour comprendre l’algorithme du sous-programme et de l’effort qui sera nécessaire pour le tester.
Le nombre cyclomatique peut être interprété comme étant le nombre minimum de cas de test qu’il faudra générer pour tester et exécuter tout le code du sous-programme. On peut l’appliquer au niveau de la méthode d’une classe.
V(G) = e - n + 1
avec e = nombre d’arcs
et n = nombre de noeuds du graphe
Le nombre pondéré de méthodes
Le WMC (Weighted Methods per Class) donne une idée de la complexité des méthodes d’une classe. Cette métrique a été proposée par Chidanber.
WMC = somme(Ci)
où Ci représente la complexité statique de la méthode i
(b) donne un indicateur sur la réutilisabilité. Le projet ROOT établit que cette métrique devrait être inférieure à vingt.
Sharble utilise cette métrique pour comparer la complexité des classes produites à partir de deux méthodes de conception différentes.
Le manque de cohésion entre méthodes (LCOM)
LCOM donne le nombre d’ensembles disjoints d’attributs dans une classe. Des ensembles sont disjoints s’ils n’ont aucun attributs en commun (Chindanber).
LCOM = nombre d’ensemble disjoints formés par l’intersection des ensembles {I1} ... {In}
avec n = nombre de méthodes de la classe étudiée
et {Ii} = ensemble des attributs utilisés par la méthode Mi
Un grande cohésion entre les méthodes d’une classe montre une bonne encapsulation. Un manque de cohésion indique qu’il serait préférable de diviser la classe en plusieurs autres classes. On peut ainsi remettre en cause une conception par la création d’une ou plusieurs classes. Ceci va rendre plus facile l’application à maintenir et à faire évoluer.
Cette métrique est donc utilisable pour détecter des défauts potentiels dans la conception objet.
Réponse pour une classe (Response For a Class)
RFC donne le nombre de méthodes pouvant être sollicitées en réponse à un message (Chidamber).
RFC = Somme RSi
RSi = 1 + Ri
où Ri = nombre de fonctions extérieures à la classe appelées par la i ème méthode
La réponse pour une classe détecte les classes dont les méthodes risquent d’avoir des performances diminuées à cause du nombre excessif d’appels à d’autres méthodes. Elle est utilisable lorsque l’on recherche des classe réutilisables. En effet, elle met en évidence les dépendances importantes des classes par rapport aux autres classes.
Le nombre de niveaux du graphe d’appel (CG-LEVEL)
Le CG-LEVEL donne le nombre de niveaux dans le graphe représentant les appels entre les méthodes d’une application. Un nombre élevé de niveaux montre une hiérarchie trop forte dans une application. Il faut alors songer à effectuer les modifications nécessaires.
Le nombre de niveaux du graphe d’héritage (IG-LEVEL)
L’IG-LEVEL indique le nombre de niveaux dans le graphe représentant les héritages entre classes. Une application avec un nombre élevé d’IG-LEVEL sera plus difficile à comprendre.
Le couplage entre objets est un indicateur de dépendance d’une classe vis à vis des autres classes. Plus le CBO est élevé, plus une classe est liée à d’autres classes. Une forte valeur de CBO doit conduire à vérifier la conception qui s’avère être peu modulaire. Cela n’aide pas à la réutilisation et à la maintenabilité.
La profondeur de la classe dans l’arbre d’héritage (DIT)
Cette métrique donne la profondeur la plus grande entre la classe et la racine. Plus une classe est située profondément dans l’arbre d’héritage, plus le nombre de méthodes dont elle hérite est potentiellement important. Son comportement est donc complexe et difficile à comprendre.
Cependant, plus une classe est située profondément dans l’arbre, plus la réutilisation potentielle des méthodes dont elle hérite est important.
Un bon compromis doit être trouvé. En règle générale, la DIT ne doit pas excéder cinq.
Le nombre d’enfants de la classe (NOC)
Le NOC indique le nombre de classes qui vont hériter des méthodes et attributs de la classe considérée. Plus le nombre d’enfants est important, plus il y a de réutilisation et plus l’effort de test est important.
Cependant, plus le nombre d’enfants est important, plus l’abstraction de cette classe est vraisemblablement erronée. Un problème de conception en est la cause.
La valeur maximale ne doit pas excédée cinq.
La MHF (Method Hiding Factor) et la AHF (Attribute Hiding Factor) quantifient l’invisibilité des méthodes et attributs des classes par rapport aux autres classes. Lorsque ces métriques sont importantes, cela signifie que la maintenabilité est elle aussi, élevée.
Les tests en objet sont à la fois similaires et différents de ceux des systèmes conventionnels. En effet, les systèmes objet peuvent être spécifiés du bas vers le haut, à partir de classes réutilisées et testées avant que le système ne soit complètement spécifié, au fur et à mesure de l’assemblage. De même, la conception d’ensemble du système peut être testée par simulation bien avant que tout objet ne soit codé. De plus, la technologie objet permet de tester l’aspect des interfaces utilisateurs du système avec les composantes opérationnelles, plutôt que séparément comme dans le cas des autres approches.
Deux sortes de tests existent. Les tests de validation répondent à la question : " A-t-on produit la bonne chose ? ". C’est un processus de comparaison entre le produit final et les besoins réels des utilisateurs. Les tests de vérification répondent à la question : " L’a-t-on produit correctement ? " C’est un processus de détection des défauts et des dérivations par rapport aux attentes des développeurs.
Les tests de vérification se subdivisent eux aussi en deux catégories. La première regroupe les tests d’unités. Ils ont la charge de tester le comportement de chaque module, sous-système, méthode et objet. La deuxième comporte les tests d’intégration. Ceux-ci vérifient que l’assemblage des unités testées effectuent le travail, sans effets de bord ou erreurs.
Les tests d’unités sont rendus plus complexes en objet par l’héritage et autres formes de polymorphisme. Par contre, les scripts de tâches permettent d’effectuer les tests d’intégration non seulement sur le code, mais aussi sur les premiers modèles objets produits par les analystes. Nous ne nous intéresserons ici qu’aux tests unitaires.
La démarche globale la plus couramment utilisée est la suivante :
Il faut considérer qu’une classe non testée ne fonctionne pas.
Une classe est valide lorsque chacune de ses instances vérifie son invariant. Elle doit aussi respecter que toute méthode appelée dans des conditions valides (c’est à dire lorsque les pré-conditions sont respectées) vérifie sa post-condition à la fin du traitement.
Il est donc nécessaire de tester les classes en activant les contrôles de pré-condition et de post-condition. Plus la rédaction des invariants, pré-conditions, post-condition est précise, moins les vérifications des tests doivent être importants.
Dans une application construite par objet, les tests unitaires s’effectuent au niveau des classes. Tester une classe, c’est appliquer pour un ensemble d’instances de test, une ou plusieurs " séquences de tests ". Celles-ci sont constituées par une suite de jeux de tests. Chacun d’entre eux définissent des envois de messages particuliers, et les résultats qu’on peut en attendre.
On définit donc, au niveau de chaque méthode, un ensemble de jeux de tests. Ensuite, on détermine au niveau de la classe, un ensemble de séquences de tests. C’est seulement après ces deux étapes que les tests unitaires sont terminés.
La technique de test employée doit assurer les propriétés suivantes :
Les tests en boîte blanche (ou tests structurels) examinent la construction interne du module en ne testant pas les données mais la physique du logiciel (c’est à dire comment il fonctionne). Ils doivent provoquer l’exécution de chacune des lignes de code au moins une fois. On utilise les cas d’utilisation (vus dans le premier chapitre) pour représenter les chemins potentiels au travers du système.
Les tests en boîte noire (ou de spécification) testent uniquement l’interface d’un objet et regardent si elle se comporte comme prévu. Les erreurs internes donnant des comportements corrects ne sont alors pas détectées car ces tests ne posent pas de regard sur le fonctionnement de l’objet.
Les langages objets se divisent en deux catégories : les purs objets comme Eiffel ou Smalltalk et les hybrides comme C++ et Pascal Object. Les premiers obligent les programmeurs à adopter un style objet, ce qui rend la période de formation plus longue. Les deuxièmes sont une transition facile pour les programmeurs connaissant le langage de base, mais sont plus sujets à risques (rédaction du code dans un style procédural classique et violation de l’encapsulation).
Malgré l’intérêt croissant pour la métrologie objet, les progrès sont encore limités et un travail d’interprétation des mesures doit être fait. Les outils automatiques de mesures proposent maintenant des solutions intéressantes.
L’utilisation des approches objets accroît la qualité du logiciel, mais elle n’assure pas l’infaillibilité du programmeur. Il est donc nécessaire de disposer de méthodes de tests adaptées au développement objet.
Afin de maîtriser une méthode quelle qu’elle soit, il est obligatoire d’en connaître ses atouts et ses faiblesses. Dans les systèmes objets, les objets sont un élément clef pour accroître la productivité en assemblant des systèmes à partir de modules réutilisables. La réutilisation est donc l’intérêt le plus souvent mis en avant, mais elle n’est pas le seul attrait de la technologie objet.
La qualité d’un système logiciel correspond à son aptitude à répondre aux besoins exprimés. B. Meyer distingue deux facteurs de qualité du logiciel : les facteurs externes et les facteurs internes. L’utilisateur seul peut détecter l’absence ou la présence des facteurs externes. Ils sont représentés par :
Les facteurs internes ne sont perceptibles que par l’informaticien. Ils se composent entre autres de :
Le problème de maintenance entraîne des facteurs tels que la validité, la robustesse, l’extensibilité, la compatibilité, etc. Afin de répondre au problème de la réutilisation, il est essentiel de résoudre et de se pencher sur les facteurs internes de la qualité. La réutilisabilité représente l’aptitude d’un logiciel à être utilisée pour fabriquer d’autres logiciels. Elle est importante car il vaut mieux réutiliser un logiciel dont la fiabilité et la validité sont prouvées que d’en développer un nouveau.
Les objets informatiques représentent des choses du monde réel. On peut donc les désigner et les manipuler de la même manière que dans le monde réel. Les applications deviennent plus simples et faciles à utiliser. Les utilisateurs peuvent aussi mieux exprimer leurs besoins puisque les modèles produits ressemblent à ce qu’ils désirent.
La flexibilité des logiciels objets permet le prototypage rapide, une facilité de construction et de réaction à l’évolution des besoins. Le résultat est que l’application reflète une meilleure compréhension des besoins de l’utilisateur, ce qui mène à une meilleure satisfaction et une meilleure productivité. De plus, moins de modifications sont nécessaires lors de la sortie du programme.
Le développement objet réduit la charge de maintenance d’une application grâce à sa modularité et au faible couplage (terme désignant l’ensemble des relations qui lient deux objets) entre les constructions orientées-objet fournies par l’encapsulation. Chaque objet présente uniquement au monde son interface publique. Les travaux internes sont masqués et peuvent être modifiés sans propager les effets des modifications sur les autres modules.
Une application peut être construite à partir de modules (ou composants) existants. S’ils sont bien testés, une application peut être construite avec une large proportion de code de haute qualité pour commencer. De ce fait, le travail de maintenance devient moins important. De plus, l’identification des parties communes à travers, voire dans des applications facilite la réutilisation du code et de la modélisation. Ainsi, le codage est réduit, et par conséquent les risques d’erreur de codage : cela réduit encore plus les besoins de maintenance.
Les ennuis de dernière minute sont plus faciles à juguler avec les méthodes objets puisque les modifications sont encapsulées dans un objet ou se traduisent par un acheminement différent des messages.
L’héritage rend le traitement des exceptions plus facile et améliore l’extensibilité des systèmes. En effet, la création de nouvelles fonctions par simple ajout d’objets enfants permet de concevoir et d’implémenter des modifications plus simplement.
L’encapsulation masque l’implémentation et ne permet à l’utilisateur que de connaître les interfaces des objets. Elle contribue donc à la sécurité.
L’approche objet gère beaucoup mieux la complexité que les autres approches. La première raison est que le système et le problème sont en étroite correspondance, de sorte que les opérations de bon sens se transposent directement dans la solution. La deuxième raison est que l’encapsulation découpe le problème en blocs cohérents, suffisamment petits et simples pour que nous les appréhendions chacun comme un tout. La dernière raison est que la réutilisation et l’extensibilité des systèmes par objets signifient que les systèmes complexes sont d’une part assemblables à partir de systèmes simples et d’autre part susceptibles d’évolution incrémentales, par petites étapes, vers des systèmes encore plus complexes.
Conceptuellement, l’orientation objet peut offrir une uniformité tout au long du cycle de développement de l’application.
Les théoriciens du logiciel soulignent depuis longtemps l’importance de la modularité. La modularité permet de décomposer un système en un ensemble de constituants, jugés individuellement plus simples. Meyer recense cinq critères :
La décomposabilité suppose que chaque module ne connaît que sa propre implémentation et non celle de ses serveurs. Les changements de conception sont ainsi isolés et n’affectent pas directement le reste du système.
Certains observateurs estiment que dans l’industrie, la réutilisation appliquée à grande échelle, permettrait d’économiser jusqu’à 20% des coûts de développement. Selon d’autres estimations, 70% des efforts des programmeurs sont dédiés à la maintenance de code existant, dont 80% se passent en corrections plutôt qu’en améliorations. Tout ce qui contribue à une meilleure spécification et à la réutilisation doit donc figurer au premier rang des priorités de l’industrie du logiciel.
La réutilisation de classes existantes conduit à des projets de meilleure qualité, avec moins de bogues et répondant mieux aux besoins de l’entreprise. Elle recourt à trois grandes techniques : la conception ascendante, l’encapsulation et l’héritage.
La conception ascendante des méthodes de développement objets accroît le potentiel de réutilisation des modules. Elle est rendue possible par le mécanisme d’encapsulation.
La fiabilité et la validité du logiciel peuvent être résolues par la réutilisabilité puisqu’elle permet d’assembler divers composants ayant déjà fait leurs preuves.
Au départ, le manque de bibliothèques d’objets commercialisées était un grave problème. L’intérêt de la réutilisation était donc remis en cause. En l’absence de ces bibliothèques, l’adoption des méthodes objets par les entreprises était réduite à néant. Ce n’est plus le cas aujourd’hui.
Par contre, la gestion de grandes bibliothèques de composants reste un problème à résoudre. Pour les organiser, deux modes principaux ont été explorés. Les classes peuvent être organisées hiérarchiquement, ce qui permet l’utilisation de browsers. L’alternative consiste à stocker des mots clefs avec chaque classe et d’effectuer la recherche, comme dans un système d’information conventionnel. Aucune de ses deux approches ne s’avèrent être idéales. Une approche combinée semblerait être la meilleure solution.
Un projet réutilisable entraîne une analyse plus importante. En effet, tous les éléments ne sont pas forcément intéressants et donc n’amènent pas à un besoin de réutilisation. C’est durant la phase d’analyse que le choix doit être fait, ce qui augmente la masse de travail à effectuer.
Lorsqu’un projet prend du retard, le temps devient compté. Or, le chef de projet peut être tenté par laisser de côté la réutilisation future afin d’avancer plus vite. Tant que des bibliothèques ne sont pas créées, le temps de réalisation d’applications s’en trouve augmenté. Le dilemme est donc de choisir le projet qui supportera en premier les méthodes objets.
Une nouvelle technologie présente peu d’aptitudes et peu d’intérêts lorsqu’elle arrive sur le marché (cf. figure 8). Au cours de sa vie, elle augmente ses capacités jusqu’à saturation ou épuisement. Cependant, sa réputation reflétera la valeur qu’on lui accorde et évoluera dans le bon comme dans le mauvais sens. Avec le temps, après les effets d’attirance de la nouveauté, elle connaît une période difficile. Ses lacunes, les fautes d’appréciation des fournisseurs sortent au grand jour.
Pendant cette même période, les capacités du produit se sont améliorées et les deux courbes se croisent au point Q. Le prix se fonde sur la valeur d’échange, qui elle-même se base la demande. La demande repose alors sur les attentes et non pas sur la valeur d’utilisation ou les aptitudes. Les consommateurs, durant la période située entre les points P et Q, paient le prix fort pour cette technologie. Ils peuvent ensuite l’acheter à très bas prix, jusqu’à ce que la situation se normalise au point R.

La difficulté pour les entreprises est de situer les méthodes de développement objets sur cette courbe. Il s’avère qu’aujourd’hui, on se situe vers le point R. Les conséquences de cette analyse sont les suivantes :
Le prix à payer par rapport à la situation où se trouvent les méthodes objets ne sont pas les seuls à prendre en compte. Les investissements dans du nouveau matériel, de nouveaux logiciels et de nouvelles méthodes sont loin d’être négligeables. A ceux-ci s’ajoutent les coûts de l’indispensable formation et les surcoûts de développement de composants réutilisables (au moins six fois plus au vu de la plupart des expériences) et de gestion de bibliothèques. En effet, avoir écrit ou acheté une gamme de classes ne résout pas tous les problèmes.
La direction doit comprendre de façon sensible les avantages, les inconvénients et les conséquences du passage à la technologie objet. Elle doit répondre à des besoins particuliers et faire l’objet d’une formation sur mesure avec l’aide d’un spécialiste externe. Le danger est de prendre les méthodes de développement objets pour un effet de mode.
Le choix de la migration vers l’objet n’a pas que des aspects positifs. Les coûts inhérents à la mise en place des possibilités de réutilisation et l’adoption de mesures nécessaires peut demander un changement de culture et des investissements conséquents.
L’organisation et la culture de l’entreprise sont bouleversées par la technologie objet. En effet, l’habitude est de récompenser analystes et programmeurs en fonction de la quantité de code produit et non de la quantité du code réutilisé. Cela implique un changement dans le mécanisme de promotion qui peut se réaliser avec plus ou moins de résistance.
Les chefs de projets sont eux aussi impliqué. Ils sont payés pour faire aboutir les projets en temps et en heure et non pour développer des projets qui profiteront aux projets suivants. Il y a là encore matière à incompréhension.
Chaque gestionnaire de l’entreprise devra être formé à cette nouvelle approche, afin d’éviter de retourner vers les approches traditionnelles combinées à des outils orientés objets. Cela demande un leadership clair et positif, une vue très nette et une concentration sans faille sur les avantages et les risques inhérents à la technologie objet.
L’attrait principal des méthodes objets se résume par le principe de réutilisation. Il ne s’obtient pas sans efforts (surcoût et envie réelle des utilisateurs) mais permet à terme d’améliorer la qualité et la productivité des développements.
Les notions d’encapsulation, de passage de messages et d’héritage accroissent l’extensibilité des systèmes et cela, d’une manière plus sécurisée.
Les atouts des méthodes objets ont aidé au développement d’applications complexes. Les faiblesses des langages de programmation objet ont donné lieu à des améliorations des bases de données qui tentent de résoudre leurs points faibles.
La gestion de projet nécessite prendre en compte la philosophie et les concepts objets, même si de nouvelles méthodes comme UML couvrent une grande partie du cycle de vie du logiciel.
Les notions d’extensibilité ont amenés le développement du middleware objet. Les deux principaux modèles sont Corba et OLE/COM. Ils tentent de répondre au déploiement des applications de la façon la plus ouverte et la plus transparente possible.
La plupart des IGU actuelles existent grâce aux méthodes de développement objets. En effet, les interfaces sont coûteuses en temps et en hommes. Les constructeurs ne peuvent donc se permettre d’engager des dépenses faramineuses tous les deux ou trois ans afin de suivre l’évolution du marché. La possibilité de réutiliser une partie de l’existant pour créer de nouvelles interfaces permet aux développeurs de faire évoluer leurs produits.
De plus, la programmation dans ces environnements devient quasiment impossible sans bibliothèques d’objets graphiques réutilisables et extensibles (par exemple, les Application Programmer Interface de Microsoft). Avec une bonne bibliothèque de classes à disposition, la programmation objet peut accélérer jusqu'à 75 % le développement d’application dans un système comme Windows.
La technologie objet apporte beaucoup car elle est presque la seule qui s’ouvre naturellement à la modélisation d’interactions déclenchées par événements (comme un clic de souris). Elle renforce ainsi la productivité par le biais de la réutilisation d’objets graphiques, en masquant la complexité et en renforçant les standards via la réutilisation de bibliothèques.
L’héritage permet au développeur de se concentrer sur les caractéristiques qui singularisent son application. Il peut se baser sur les schémas d’applications génériques pour la réalisation d’interfaces graphiques plutôt que d’avoir à réinventer la solution du début à la fin.
La plupart des langages de programmation objet permettent de créer, manipuler et détruire des objets en mémoire virtuelle. La durée de vie des objets se limite donc à la durée d’exécution du programme. Il est possible de prolonger la vie des objets en les copiant dans des fichiers. Ce couplage fournit une forme primitive de persistance des objets qui pose de sérieux problèmes (mauvaise performance, gestion de la concurrence et de l’intégrité des données, …).
Les domaines d’application comme l’ingénierie, la bureautique et l’administration de réseau ne peuvent être gérées par des SGBD relationnels. En effet, le modèle relationnel supporte difficilement les objets complexes qui engrangeraient la création d’un trop grand nombre de tables. De plus, les SGBD ne gèrent que des transactions courtes.
L’approche relationnelle-objet, représentée par le standard SQL3, est une solution à ces problèmes. Elle intègre SQL dans un langage à objets afin de prendre en compte les propriétés des objets. Elle ne nécessite pas une conversion majeure des catalogues de données existants. La structure des données des objets est stockée dans une base de données relationnelles.
La correspondance entre les objets et les tables est difficile à gérer car une classe peut correspondre à une ou plusieurs tables, et une table peut correspondre à plusieurs classes. Un autre problème est que les données de l’objet sont stockées, mais pas leurs méthodes. Cela implique l’utilisation de fichiers externes à la base de données, comprenant ces méthodes. Des recherches ont lieu afin d’intégrer toutes les propriétés des objets dans le modèle relationnel.

Les systèmes de gestion de base de données objet (SGBDO), conçus pour le stockage et le partage des objets, sont une autre solution pour la gestion des objets persistants. Ils nécessitent trois composants : les gestionnaires d’objets, les serveurs d’objets et les magasins d’objets. Les applications (outils + langages) interagissent avec les gestionnaires d’objets, qui travaillent à travers des serveurs d’objets pour obtenir un accès à des magasins d’objets (cf. figure 9).
ODL est un langage de spécifications de schémas. Il permet de définir les types d’objets (propriétés et signatures) mais pas leur implémentation. Il ne sert qu’à l’écriture des opérations et des programmes d’application.
OML est un langage de manipulation d’objets intégré à un langage de programmation objet. Il permet la navigation, l’interrogation et la mise à jour de collections d’objets persistants.
Le langage OQL d’interrogation est proche de la syntaxe de SQL. OQL est particulièrement puissant pour manipuler les collections d’objets complexes. Il peut être utilisé dans un langage de programmation ou comme un langage indépendant.
Le gestionnaire d’objets gère un cache local d’objets pour chaque application. Ce cache agit comme un espace de travail temporaire. La création et la modification d’objets sont effectuées dans le cache, puis validées dans la base de données une fois que les opérations sont terminées. Ce processus est totalement transparent pour l’utilisateur. Les objets sont accédés à l’aide de pointeurs.
Le serveur d’objets s’occupe d’un cache séparé d’objets qui peuvent être partagés par plusieurs applications. A travers ce cache, les serveur coordonne les accès aux magasins d’objets grâce à des mécanismes de verrouillage. Ce mécanisme doit être capable de gérer les transactions longues (pour la CAO par exemple) aussi bien que courtes.
Les magasins d’objets sont les systèmes physiques de stockage. Ils représentent la véritable base de données résidant sur le disque.
Les bases de données par objets minimisent le swap des objets en mémoire, augmentent les possibilités de partage, de distribution, de sécurité ainsi qu’un meilleur contrôle des versions. Elles comblent le vide sémantique entre les objets et concepts du monde réel, et leur représentation dans une base de données.
La transition vers les méthodes de développement objet nécessite de répondre à plusieurs questions clés au niveau de l’entreprise. Ces questions concernent l’opportunité d’une telle transition, des coûts, de l’allocation des ressources et la préservation de l’investissement dans les systèmes existants.
Les étapes d’un processus de développement objet n’ont pas à être exécutées dans un ordre séquentiel strict. Bien que certaines étapes dépendent des produits des autres, les phases se regroupent, et chaque étape peut influencer n’importe quelle autre.
Après l’analyse des besoins, la première étape est de modéliser le problème à résoudre. Pour construire ce modèle, les objets et les classes doivent être identifiés ainsi que leur comportement et responsabilité (cas d’utilisation, CRC). Ensuite, il faut épurer le premier modèle afin d’effacer les objets incorrects ou non-nécessaires (analyse du comportement des objets). Le produit de cette étape est un modèle objet.
Le modèle objet a généralement une portée supérieure à celle demandée par l’utilisateur. La deuxième étape se préoccupe donc de déterminer la portée approximative de l’application.
La troisième étape consiste à transformer le modèle pour des raisons conceptuelles. Les transformations de classes dues à un regroupement conceptuel peuvent impliquer : grouper les classes très simples en classes plus complexes et organiser les classes en hiérarchie.
Au cours de la quatrième étape, la conception du modèle de l’application est définie. Elle comprend la conception des algorithmes d’implantation des opérations, l’optimisation des chemins d’accès aux données, les ajustements de la hiérarchie d’héritage, l’implantation des associations et la définition de la représentation des attributs. C’est ici, que les nouvelles classes servant uniquement pour des raisons d’implantation, doivent être crées.
La cinquième étape se focalise sur l’interface utilisateur et ses interactions. Un choix sur le style de contrôle doit être fait. En règle général, on utilise le style de contrôle événementiel qui nécessite l’existence d’une classe contrôleur. Cette classe représente les tâches utilisateur et traite la synchronisation des requêtes.
La sixième étape s’intéresse à la partie représentation de l’interface utilisateur. Ce que l’utilisateur voit sur son écran correspond à une information stockée dans le modèle. Cette vue est donc dépendante du modèle. L’utilisateur participe activement à cette étape.
La huitième étape se préoccupe de la conception de l’information persistante. Le choix d’un catalogue de données persistantes et les exigences d’implantation doivent être soigneusement considérés et définis lors de cette étape (cf. le chapitre consacré aux objets dans les bases de données).
La neuvième étape correspond à l’implantation et les tests de l’application. Il existe un grand choix de langages orientés-objet sur le marché. Le choix d’un langage dépend de considérations concernant l’application, la plate-forme, les compétences et les caractéristiques du logiciel. Les différents outils existants (générateurs d’écrans, outils CASE, …) doivent être considérés comme des éléments clefs dans la réussite de l’implantation.
Le retour d’informations de la part de l’utilisateur est le véritable test de conformité de l’application aux besoins. Cette neuvième étape doit solliciter l’utilisateur le plus tôt possible afin de rendre l’application la meilleure possible.
La dernière étape consiste à prendre de petites phases du développement et de les retourner à une étape appropriée du plan. Ensuite, on applique itérativement ce qui a été appris. Aux niveaux inférieurs de conception, les opportunités de réutilisation peuvent apparaître plus évidentes. La possibilité d’itérations mène à un code qui reflète mieux les besoins de l’utilisateur et qui nécessite moins de maintenance.
La notation UML représente l’état de l’art des langages de modélisation objet. Elle se place comme le successeur naturel des méthodes de Booch, OMT et OOSE vues dans le premier chapitre.
Partant de la constatation que les différences entre les méthodes s’amenuisent, Jim Rumbaugh et Grady Booch décident fin 1994, d’unifier leurs travaux au sein d’une méthode unique : la méthode unifiée. Un an plus tard, ils sont rejoints par Ivar Jacobson. Ils se sont alors fixés les objectifs suivants :
La première version a vu le jour en octobre 1995 sous le nom d’Unified Method V.08. Puis, la méthode unifiée se transforme en UML, après différentes modifications, en 1996. Il se crée alors un consortium de plusieurs grandes entreprises (dont DEC, ORACLE, IBM, ...) visant à la définition d’UML 1.0. Sa standardisation par l’OMG s’est effectuée en 1997.
UML définit neuf sortes de diagrammes (cf. figure 10) afin de représenter les différents points de vue de modélisation. Un diagramme contient des attributs de placement et de rendu visuel qui ne dépendent que du point de vue. Selon le niveau de détails souhaité, le diagramme peut montrer l’ensemble ou seulement une partie des éléments de modélisation.

UML utilise la notion de paquetage qui aide à une meilleure visibilité du système. Un paquetage est un regroupement d’éléments selon un critère purement logique. Les paquetages sont représentés graphiquement sous la forme d’un dossier.
Les cas d’utilisation
Ils sont des classes dont les instances sont les scénarios. Dès qu’un acteur interagit avec le système, le cas d’utilisation instancie un scénario. Celui-ci correspond au flot de messages échangés par les objets. Les scénarios, instances du cas d’utilisation, sont représentés par des diagrammes d’interaction (collaboration et séquence).

Le passage à l’approche objet s’effectue en associant une collaboration à chaque cas d’utilisation. Une collaboration décrit des objets du domaine, les connexions entre ces objets et les messages échangés (cf. figure11).
Les diagrammes de classes
Ils expriment la structure statique d’un système en terme de classes et des relations entre ces classes. Les classes sont représentées par des rectangles compartimentés. Ceux-ci contiennent l’identifiant unique, les attributs et les opérations de la classe.
Les diagrammes d’objets
Ils montrent des objets et des liens. Comme les diagrammes de classes, les diagrammes d’objets représentent la structure statique. La notation retenue est dérivée de celle des diagrammes de classes.
Ils s’utilisant principalement pour présenter un contexte, par exemple avant et après une interaction, mais également pour faciliter la compréhension des structures de données complexes, comme les structures récursives.
Les diagrammes de collaboration

Ils expriment le contexte d’un groupe d’objets et l’interaction entre ces objets. Le temps n’est pas représenté da manière implicite. Chaque message est donc numéroté (cf. figure 12).
Les objets qui possèdent le flot de contrôle sont dits actifs. Eux seuls peuvent activer, via l’envoi d’un message un objet passif. Le résultat, s’il existe, est alors renvoyé et réactive l’objet de départ.
Les diagrammes de séquence
Ils montrent les interactions entre objets selon un point de vue temporel. Le contexte des objets n’est pas représenté de manière explicite comme dans les diagrammes de collaboration. La représentation se concentre sur l’expression des interactions.
Deux grandes catégories d’envois de messages se distinguent :
- asynchrone : l’émetteur est bloqué et attend que l’appelé ait fini de traiter le message
- synchrone : l’émetteur continue son exécution après l’envoi du message
Le diagramme de séquence peut être complété par des indicateurs textuels, exprimés sous la forme de texte libre ou de pseudo-code (cf. figure 13).

Les diagrammes d’états-transitions
Ils visualisent des automates d’états finis. Le comportement des objets peuvent être décrit de manière formelle au moyen d’un automate relié à la classe considérée. Les automates retenus par UML possèdent trois concepts. L’orthogonalité (par exemple des classes sans rapports entre elles), l’agrégation et la généralisation (super-état regroupant différents états afin d’améliorer la lisibilité).
Un automate est une abstraction des comportements possibles (cf. figure 14). Chaque objet suit globalement le comportement décrit dans l’automate associé à sa classe et se trouve à un moment donné dans un état qui caractérise ses conditions dynamiques.

L’état d’un objet regroupe les valeurs contenues par ses attributs et ses liens avec d’autres objets. La transition montre le passage d’un état à un autre état.
Les diagrammes d’activité

Ce sont en fait une variante des diagrammes d’E-T vu plus haut. Ils sont organisés par rapport aux actions et sont principalement destinés à représenter le comportement interne d’une méthode ou d’un cas d’utilisation (cf. figure 15).
Chaque activité représente une étape particulière dans l’exécution de la méthode englobante. Les activités sont reliées par des transitions automatiques. Lorsqu’une activité se termine, la transition est déclenchée et l’activité suivante démarre.
Les diagrammes de composants
Ils décrivent les éléments physiques et leurs relations dans l’environnement de réalisation. Ils montrent les choix possibles de réalisation (cf. figure 16). Ils se composent :
- de modules : ce sont toutes les sortes d’éléments physiques qui entrent dans la fabrication des applications informatiques (fichiers, bibliothèques, ...)
- de dépendances entre composants : ce sont les relations de services offerts entre composants
- de processus et de tâches : ce sont les composants qui possèdent leur propre flot de contrôle
- de programmes principaux
- de sous-programmes : regroupent les procédures et les fonctions qui n’appartiennent pas à des classes
- de sous-systèmes : c’est un regroupement de différents composants dans des paquetages

Les diagrammes de déploiement

Ils montrent la disposition physique des différents matériels (appelés ici nœuds) qui entrent dans la composition d’un système et la répartition des programmes exécutables sur ces matériels (cf. figure 17).
Ils peuvent aussi représenter des classes de noeuds ou des instances de noeuds. Ils décrivent également les liens de communication entre les différents nœuds.
La fusion des méthodes d’UML facilite la communication et la réutilisation mais peut aussi avoir un effet pervers : s’imposer comme un standard incontournable. Cela risque d’inhiber d’autres méthodes plus modernes et mieux adaptées aux nouvelles applications.
UML est utilisée par Alcatel Space Industries depuis 1997 au sein du projet SkyBridge (système de communication large bande à base de satellites en orbite basse). Les schémas UML ont permis des échanges avec la société Sharp au Japon. C’est elle qui gère le terminal d’accès au réseau satellite. UML sera peut-être la solution d’un langage commun de projets internationaux.
Le langage OO-COBOL est une nécessité pour les utilisateurs désirant bénéficier de la réutilisation et de l’extensibilité tout en protégeant l’énorme investissement que représente le code existant. Celui-ci est estimé à près de 70 milliards de lignes de par le monde.
OO-COBOL permet :
Micro Focus propose Object COBOL Developer Suite pour Unix qui comprend des bibliothèques de classes, une extension des applications au Web et un accès à la technologie Corba. Il n’existe pas à ce jour de solution identique pour les plates-formes Windows.
Une autre solution pour mettre au goût du jour COBOL est proposée par Intercomp depuis fin 1998. Javamaker est un outil de conversion des applications COBOL en Java. Ces applications deviendront alors portables sur tout système utilisant la machine virtuelle Java.
La plus grande difficulté de ces deux solutions provient du fait que les utilisateurs du COBOL ne sont peut être pas prêts à se tourner vers un langage et une philosophie objets.
Les outils objets connus sous le nom d’AGL (Atelier de Génie Logiciel) ou CASE (Computer Aided Software Environment) ont pour objectifs l’accroissement de la productivité, des compétences et de la qualité. Ils doivent donc aider à formuler les produits et supporter le processus aboutissant à leur construction. Ceux-ci répondent à des besoins basiques et avancés :
Les ateliers de développement (L4G et ADE) permettent généralement de construire des applications client-serveur autour de base de données à l’aide d’objets graphiques prédéfinis et d’un langage de programmation objet propriétaire.
Les bibliothèques de classes d’objets systèmes ou métiers peuvent être pré-assemblées pour construire des infrastructures (frameworks). La fonction d’un framework est de présenter au développeur d’applications une interface simple, pour rendre un service simple ou un ensemble de services, et de le faire de façon efficace et fiable. Différents types de frameworks existent :
Le dernier outil étudié dans ce paragraphe se dénomme patron. Il identifie un problème récurrent à résoudre dans un domaine particulier en se basant sur les expériences passées. Ensuite, il propose une solution possible et correcte pour y répondre. Enfin, il offre les moyens d’adapter la solution au contexte spécifique. Les patrons objets capitalisent des savoir-faire métiers ou généraux. Ils sont classifiés en fonction de l’étape du cycle de développement à laquelle ils correspondent : on parle alors de patrons d’analyse, de patrons de conception (design patterns) ou de patrons d’implantation. Leur application est du type " imitation " d’un patron existant puis son adaptation afin de répondre à la nouvelle demande.
L’objectif principal de l’Object Management Group (crée en avril 1989) est d’établir une architecture et un ensemble de spécifications afin de créer des applications distribuées et intégrées. La réutilisabilité, la portabilité et l’interopérabilité des composants sont le soucis majeur de cette organisation.
L’OMG est formée par plusieurs entreprises (IBM, Sun, HP, ...) et des éditeurs de logiciels. Son but est de définir des spécifications que les membres vont suivre. Ils se sont engagés à supporter activement et à se conformer aux directives de l’OMG dans leurs produits.
L’OMG utilise deux schémas basiques. Le premier est le Modèle Objet. Il décrit les relations, les attributs et les opérations d’un objet. Il fournit un cadre conceptuel pour les technologies proposées. Le deuxième se nomme le Modèle de Référence. Il définit les composants nécessaires au fonctionnement des objets entre eux. Il se divise en quatre parties :
Ces éléments garantissent simplement l’interopérabilité avec d’autres objets développés sous la même architecture. Des objets crées avec Smalltalk seront alors capables d’utiliser les services d’objets implantés en C++. L’ensemble de ces objets constituent la base commune de bibliothèques de classes réutilisables.
CORBA est un exemple d’architecture issue de l’OMG. Elle introduit la notion d’objet dans le traitement distribué et met en œuvre le modèle client/serveur avec un intermédiaire : l’ORB (ou agent). Son rôle est d’identifier le serveur capable d’offrir le service demandé et de transmettre la requête. Le client ne connaît donc pas l’adresse du serveur et vice versa. Seul l’agent connaît leurs adresses respectives. L’ajout de serveurs ou de clients ne nécessite que la modification de l’agent.
CORBA sépare le processus client du processus serveur (cf. figure 18). Ceci permet de changer la manière dont un serveur accomplit une tâche sans affecter la façon dont un client en fait la demande. Cette séparation est rendue possible par la communication sous forme de requête entre le client (qui contient les opérations) et le serveur (qui englobe les méthodes). Les requêtes intègrent la notion d’interface. L’interface décrit les opérations sur les objets qui peuvent être demandées par un client. Cette interface est écrite dans le langage IDL (Interface Language Interface).C’est elle qui rend l’interopérabilité possible.

L’architecture de CORBA se décompose en trois niveaux de fonctionnalités. L’échangeur de messages (ORB) est le bus commun d’échange de requêtes entre objets. Les services objets (OS) augmentent et complètent les fonctions de l’ORB (ajout de la création/destruction des objets, persistance, …). Les utilitaires communs (CF) rassemblent les composants de plus haut niveau s’appuyant sur les services. On y trouve les utilitaires systèmes de configuration, d’installation, de gestion etc… Ces différents niveaux sont utilisés par des objets applicatifs (Business Object).

Cette architecture assemble autour d’un bus logiciel des composants de différents niveaux capables d’échanger des requêtes, ceci sur toute plate-forme, quelque soit le système d’exploitation, le réseau et le langage de programmation (cf. figure 19).
CORBA utilise l’héritage (simple et multiple) comme technique de réutilisation du code. Les opérations les plus générales sont associées à la classe de plus haut niveau (classe racine) afin d’être mises à la disposition des autres classes par simple héritage. Tout changement dans la classe racine est induit au niveau des sous-classes. L’utilisateur devient donc tributaire de l’évolution de ces classes. De plus, toute nouvelle version implique la possibilité de non-compatibilité entre celle-ci et la version précédante.
Une version légèrement modifiée d’OpenDoc car utilisant les services définis par l’OMG, sert de standard pour la gestion de documents composés de CORBA. Un document composé est un document comportant différentes sortes de données dans un même fichier (tableaux, dessins, vidéos, …). OpenDoc permet la communication entre objets résidant sur la même machine ou sur des machines distinctes.
Corba 3 est apparue sur le marché fin 1999. Elle propose une véritable plate-forme destinée à la construction, à l’assemblage et au déploiement de composants avec une philosophie " plug and play ".
OLE/COM est le middleware objet de Microsoft. Il repose sur le modèle COM qui est une extension du modèle objet d’OLE 2.0. OLE facilite la gestion de documents composés et offre un ensemble d’interfaces (orientées objet) de communication entre applications.
Le modèle objet COM définit des mécanismes pour la création d’objets ainsi que pour la communication entre clients et objets distribués à travers un réseau par un échange de code binaire de composants. Comme CORBA, il utilise les interfaces pour la définition des fonctions des objets. Un client accède aux objets COM via des pointeurs contenus dans les interfaces. Le pointeur référence une table d’adresses des fonctions de l’interface. Il n’est pas possible d’accéder directement à l’objet en lui-même.

L’utilisateur découvre les interfaces d’un objet par l’appel d’une interface standard appelée Iunknown (cf. figure 20). Elle est la racine de toutes les classes fournissant des fonctions de base. Elle permet donc de découvrir dynamiquement les autres interfaces d’un objet, si celles-ci existent. IUnknown gère des compteurs de références qui récupèrent de la place pour les objets qui ne sont plus référencés.
Le support d’objets répartis permet l’accès aux interfaces d’objets distants, gérés par un processus différent (EXE). Le processus serveur peut être local ou distant. OLE assure la transparence au type de serveur pour tout objet client. Pour cela, différents composants sont mis en jeu (cf. figure 21). Un service de localisation et de lancement en exécution du serveur est fourni. Ce service, appelé SCM (Service Control Manager) est chargé de la localisation du serveur par accès à l’annuaire système. Ensuite, il active ou prend contact si le serveur est actif. L’envoi de messages est basé sur le RPC (Remote Procedure Call) de DCE. Il y a simplement création d’un objet procuration (proxy) émetteur sur le client et d’une souche réceptrice sur le serveur.
COM intègre les fonctions de base pour le système réparti alors qu’OLE se préoccupe plus des services évolués. Ces différents services sont les suivants :
Dans COM, la réutilisation du code est réalisée par agrégation. Un objet peut contenir d’autres objets et offrir leurs interfaces comme si elles lui appartenaient. Un tel objet représente l’agrégation des interfaces des objets qu’il contient. De plus, chaque interface est indépendante des autres. Il en résulte qu’un objet possède généralement plusieurs interfaces. Un changement dans une interface affecte seulement les objets qui l’utilisent. Mais, un objet agrégé peut utiliser des routines provenant de bibliothèques extérieures. Tout changement dans ces bibliothèques peut affecter les objets qui les utilisent.
Les concepts objets ont aidé au développement plus facile d’applications. Nous n’avons traité ici que les IGU, mais ces concepts ont aussi servi dans les domaines de l’intelligence artificielle, la CAO, les applications temps réel, etc. Une gestion de projet objet doit être mise en place afin de suivre le développement de ces applications.
UML représente une bonne unification des méthodes, malgré ses quelques imperfections. Elle a été adoptée dernièrement par France Telecom pour son projet de réécriture de l’application Mercure (application client-serveur de gestion des clients professionnels).
Les applications objets nécessitent la gestion d’objets persistants. Deux solutions sont offertes à l’utilisateur : les bases de données objets et les bases de données relationnelles objets. Les premières sont adaptées aux langages de programmation objet alors que les deuxièmes tentent d’intégrer les avantages des bases objets et des bases relationnelles classiques.
Corba et COM se sont d’abord concrétisés par des produits difficiles à mettre en œuvre. L’évolution des environnements de développement et des serveurs applicatifs ont contribués à améliorer ces deux middlewares objets. Ils se livrent aujourd’hui à une guerre sans merci afin de remporter l’adhésion des utilisateurs.
Le cycle de vie du logiciel est aujourd’hui couvert entièrement par les méthodes objets. Les différents travaux sur les phases d’analyse et de conception ont permis une évolution visant à unifier les méthodes et mieux maîtriser l’implantation des applications. Les outils se sont eux aussi mis au goût du jour et répondent de mieux en mieux aux attentes des utilisateurs, même s’il n’existe pas encore de produit parfait (existeront-il un jour ?).
La réutilisation et l’ouverture sont les chevaux de bataille de la technologie objet. Ces deux facteurs de qualité ne sont pourtant pas toujours obtenus sans mal. Ils nécessitent des compétences pointues dans le domaine , une bonne compréhension des atouts et des faiblesses de l’objet et un investissement tant humain que budgétaire non négligeable. L’engagement total des cadres supérieurs est essentiel dans la réussite d’un projet objet.
Les méthodes de développement objets ont fait naître de nouveaux métiers, comme le modélisateur d’objets, le superviseur de bibliothèques, l’architecte de réutilisation, etc. Ils sont un passage obligé afin de gérer au mieux les projets informatiques. L’application du modèle objet s’est aussi étendue à la conception des systèmes d’information, en le réduisant en différents sous-systèmes et réagissant par rapport à des évènements.
Le modèle objet s’impose pour simplifier les changements de version des progiciels et augmenter la capacité de traitement en ajoutant des serveurs sans modifier l’application. Corba et Com répondent à ces objectifs en utilisant des concepts différents. Ils s’attaquent aujourd’hui aux ERP en améliorant l’ouverture (Internet), la modularité et les performances de leur produit respectif. Il s’avère que Corba est pour le moment préféré à son concurrent.
Les années 2000 seront sûrement les années objets. Il est certain que les méthodes de développement objets ne sont pas encore la panacée pour réussir un projet informatique, mais elles tendent à atteindre ce but et ont atteint une maturité suffisante. Une de ses futures améliorations sera sa fusion avec les méthodes formelles qui utilisent des supports mathématiques afin de définir rigoureusement les concepts. Ces deux méthodes sembleraient être complémentaires.
J. Brès, Ateliers de génie logiciel : réalités et tendances, Masson, Paris, 1994, 253 p
M. Bouzeghoub, Les objets, Eyrolles, Paris, 1997, 450 p
B. Coulange, Métrologie et objets, Hermès, Paris, 1998, 364-444 p
I. Graham, Méthodes orientées objet, International Thomsom Publishing, Paris, 1997, 480 p
I. Graham, Migrer vers la technologie objet objets, International Thomsom Publishing France, Paris, 1997, 552 p
P. Jaulent, Génie logiciel : les méthodes SADT, SA, E-A, OOD, HOOD, …, A. Colin, Paris, 1990, 288 p
G. Panet, Merise/2, Modèles et techniques MERISE avancés, les Editions d’Organisation, Paris, 1994, 366 p
R. Moreau, L’approche objets : concepts et techniques, Masson, Paris, 1995, 302 p
J. Moréjon, Merise : vers une modélisation orientée objet, les Editions d’Organisation, Paris, 1994, 255 p
P-A. Muller, Modélisation objet avec UML, Eyrolles, Paris, 1997, 421 p
C. Oussalah, Génie objet : analyse et conception de l’évolution, Hermès science publications, Paris, 1999, 489 p
C. Oussalah, Ingénierie objet : concepts et techniques, InterEditions, Paris, 1997, 424 p
D. Serain, Le middleware, concepts et technologies, Masson, Paris, 1997, 214 p
D. Tkach, La technologie objet dans le développement d’applications, Vuibert, Paris, 1998, 204 p
http://www.01-informatique.com
http://www.csioo.com/cetusfr/software.html
http://jafar.uqar.uquebec.ca/raroygil/inf115/chapitre1.html
http://www.merant.fr
http://www.netinfo.fr/objectland/Langages/n9.94/OMT.html
http://www.objs.com/x3h7/oocobol.htm